Où l’on parle choix de microcontrôleur. Je le sors de la série des Fuzzquest, maintenant c’est un projet à part entière.
Nucleo ou STM32 en direct ?
La dernière fois, je me demandais si je n’allais pas intégrer directement le MCU sur la carte, sans passer par une Nucleo, pour gagner de la place. J’avais un peu peur d’avoir des problèmes pour développer avec ce setup. En vrai j’ai regardé, et ça n’a pas l’air si compliqué que ça.
Developpement
En fait sur une Nucleo on peut déconnecter la partie ST-link sans casser la carte, et les signaux SWD sont disponibles sur des connecteurs. Donc pourquoi se priver ? Ce n’est pas totalement gratuit, vu qu’il va falloir que j’intègre l’alim et le circuit de reset et l’oscillateur. Je vais largement repomper le schéma d’une Nucleo, c’est fait pour ça d’ailleurs.
Il y a quand-même une chose que je vais perdre en ne prenant pas une Nucleo : le VCOM intégré. Pour le debug ce n’est pas forcément grave, il faut juste que je n’oublie pas de donner la possibilité de connecter le RX et TX correspondant sur la Nucleo qui me servira de programmateur. Donc soit j’utilise un boîtier USB-UART, soit j’implémente de l’USB et je fais un driver et tout … Grmpf … D’un seul coup j’ai moins envie de me passer de Nucleo, tiens …
Une autre méthode plus simpliste consiste à passer par le bootloader intégré du STM32, qui fait de l’UART - voire de l’USB ou de l’Ethernet pour certains modèles. C’est d’ailleurs la méthode de programmation “de base”, et ça nécessite uniquement de l’UART, donc sonde USB-UART standard ça suffit. C’est décrit plus en détail ici. C’est simple, mais ya pas de debug, donc la méthode précédente avec une Nucleo/ST-link est quand-même plus pratique. Après, je peux envisager de mettre un FTDI USB-UART directement sur la carte. C’est pas donné (4€ pièce sur Farnell), mais ça permettrait d’avoir de l’USB qui fonctionne. Tiens, d’ailleurs je pense que je vais pas me prendre la tête et je vais faire ça. Comme ça quand je voudrais faire de l’interface, je ferai du scripting en UART vers le VCOM. Ce n’est pas très satisfaisant au niveau open-source, vu que ça se base sur les drivers FTDI, et que la politique de FTDI est … hum … contestable, mais bon, pas tout à la fois. Je provisionne l’USB FTDI dans un premier temps, et je ferai un USB-direct plus tard.
Alimentation
Les MCUs que je vise s’alimentent en 3.3V, mais je vais quand-même avoir besoin d’un 5V pour les composants logiques. Après je pourrais aussi faire un seul gros 3.3V, utiliser uniquement des composants LVCMOS qui marchent en 3.3V, alimenter aussi les LEDs / 7-segments en 3.3V, mais j’ai un peu peur que les résistances de limitation de courant doivent être énormes, donc je vais faire un rail 5V.
Sur les Nucleo pour le 5V ils ont fait simple et mis un LD1117, régulateur linéaire, ce qui fait qu’on ne peut pas mettre des tensions très élevées en entrée parce que ça risque de le faire surchauffer. Pour ne pas être emmerdé je vais mettre un buck à la place, genre celui que j’ai fait sur une carte pour Trublion - un LM2674. C’est un composant assez courant, facile à mettre en œuvre, pas trop cher, avec un boîtier gérable (SOIC). Et ensuite je me prend sur le 5V pour générer le 3.3V, avec un LDO. Sur les Nucleo ils utilisent un LD39050 qui est en QFN, donc no fucking way. Pour l’alimentation du MCU de la partie ST-link ils ont mis un LD3985 qui est en SOT23-5. C’est un tout petit LDO qui sort 150mA max. Sera-t-il suffisant ?
Pour déterminer la consommation, il faudrait déjà savoir quel modèle de MCU je vais utiliser. A priori je vais rester sur du STM32F4 ou moins, et je ne vais pas aller au-delà de 100MHz (doigt mouillé …). Comme les consommations sont données en µA / MHz, si je veux utiliser ce LDO je dois me limiter à 150000/100 = 1500µA / MHz. Sur cette catégorie on à, à la louche:
- STM32F40x : 110-130µA / MHz
- STM32F41x : 90-100 µA /MHz
- STM32F42x : 210µA / MHz
- STM32F43x : 210µA / MHz
- STM32F44x : 170µA / MHz
- STM32F4x5 et STM32F4x7 : 220µA / MHz
- STM32F46x et STM32F47x : 280µA / MHz
… Même les plus gros ne consommeront pas plus que \~30mA à pleine charge … Donc le LD3985 tiens le courant. Niveau dissipation il va se prendre un dropout de 5 - 3.3 = 1.7V, donc avec 30mA il va dissiper 1.7 x 0.03 = 50mW. Avec un Rth-ja de 255°/W ça fait une élévation de 0.05 x 255 = 13°C, largement supportable.
J’avais jamais trop regardé l’efficacité énergétique des STM32, et je dois avouer que si les chiffres des datasheets sont vrais - improbable qu’ils soient faux - on a fait un bond fantastique en quelques années. Pour mémoire, quand j’ai commencé à bosser il y a 10 ans, je bossais sur des Infineon Tricore cadencés à 180MHz, et qui consommaient bien leurs 300mA, donc une efficacité de \~1700µA/MHz. Là sur les “petits” on est à 10 fois mieux ! Je veux bien que ce soit difficilement comparable (pas la même finesse de gravure, pas la même archi …) mais quand-même, je suis impressionné.
Reset et clock
Pour la clock, je vais mettre la même chose que sur la Nucleo : quartz à 8MHz. Je suis très tenté de mettre un résonateur pour que ça prenne moins de place … Après il faut que je vérifie ce qui est requis pour faire de l’USB, car je provisionnerais bien un USB, pour plus tard …
Pour le reset, visiblement il n’y a pas besoin de circuit externe, en tous cas il n’y en a pas sur la Nucleo, je vais rester là-dessus.
Choix du MCU
Le problème avec les STM32 c’est qu’il y a tellement de modèles différents que c’est l’enfer dès qu’il faut choisir …
Bon, on a tous nos ordres de grandeur, maintenant il faut choisir le modèle. Quels sont les critères ?
- Puissance de calcul : pas vraiment déterminant, mais pouvoir faire des multiplications / divisions en unsigned sur 32 bits sans trop que ça bouffe de cycles serait pas mal.
- Mémoire : d’expérience 128MB de Flash c’est largement suffisant pour mettre une appli, 64kB pour un bootloader. Si je veux avoir quelques wavetables basiques, ça devrait être suffisant. Pour la RAM j’ai du mal à dimensionner, mais je pense que la Flash sera menante sur le choix. En gros : je vais choisir en fonction de la Flash, et j’assumerai la quantité de RAM qui sera fournie dedans. Je pense qu’il faut que je prenne au moins 256kB de Flash pour être tranquille.
- NVM : idéalement il faudrait qu’il ait de l’EEPROM intégrée. Mais au pire je peux m’en sortir avec de la DataFlash. Surtout que les seuls qui en disposent sont dans la série STM32L1xx, limités à 32MHz et 3 SPI max … Ce qui est un peu juste je pense.
- Prix : pas vraiment menant, les STM32F4 sont dans les 4-7€ pièce, c’est pas la mort.
- Boitier : QFP64 ou QFP100 max, mais en fait ça va dépendre du nombre d’IOs. En tous cas un boîtier avec des pattes, donc QFP / LQFP.
Au niveau périphériques:
- SPI : il m’en faut au moins 4 si je mets une EEPROM externe, au moins 3 si je pars à utiliser la Flash interne uniquement => 3 x 3 + 3 (chip select) = 12 pins
- Timers : 2 PWMs par VCO donc 4, 2 pour les DAC, 3 ICs en entrée, et il me faut des compteurs internes pour l’applicatif, donc idéalement une dizaine ça serait bien. Au pire les PWM je peux les synchro et utiliser plusieurs canaux d’un même timer, donc ce n’est pas très critique. Mais idéalement au moins 7 timers => 7 pins
- ADC : 2 détecteurs d’enveloppe, disons deux pédales d’expression pour avoir de la marge, et plusieurs mesures analogiques sur la FF et en miroir sur la ref, je pense 3 de chaque côté, donc au moins 10 canaux. Au pire je peux multiplexer avec un CD4051, mais je préférerais éviter => 10 pins
- UART : 1 pour la comm avec le ST-link, 1 pour la com directe si je l’implémente comme ça, 2 pour MIDI in/out, donc au moins 4. Bon, les UART sont rarement dimensionnant sur les MCUs modernes, yen a toujours plein => 4 x 2 = 8
- USB : nice to have, je vais y traiter à part => 2 pins
- GPIO : en listant tout ce dont j’ai besoin, à la grosse il me faut 25 GPIOs, à ajouter aux reste des interfaces, ça fait un total de 60. Avec autant de GPIO, pas le choix, c’est au moins 100 pattes sur le boîtier. Pour ne pas surdimensionner je vais donc partir sur du LQFP100.
- DSP : m’en fous, tant qu’il y a un diviseur HW pas trop dégueu pour les calculs de mise à l’échelle.
Tant que j’y suis et que j’y pense il faut que je fasse un point sur la NVM et le bootloader.
Mémoire non-volatile et bootloader
https://github.com/akospasztor/stm32-bootloader
Solutions techniques
La mémoire non-volatile (NVM, Non Volatile Memory) disponible sur un système embarqué à base de microcontrôleur peut être de plusieurs types:
- Flash embarquée sur le MCU
- EEPROM embarquée sur le MCU
- EEPROM externe (SPI ou I²C)
- Flash externe (SPI, I²C, sur bus parallèle)
- Stockage de masse (clé USB, disque dur …)
Dans notre cas, on ne va parler que de la mémoire embarquée dans le MCU, et un peu d’EEPROM externe.
Besoins fonctionnels
Déjà il faut expliquer ce qu’on a besoin, et donc ce que contient fonctionnellement la NVM. On va y mettre, de base, le code programme, mais elle doit aussi contenir des données qu’on pourrait mettre dans le code programme, mais qu’il est plus pratique de pouvoir modifier sans recompiler un binaire. De plus, elle va contenir des données qui changeront d’une pièce à l’autre (paramètres de calibration fin de chaîne, numéro de série), et des données qui changeront pendant la vie du produit (presets, réglages qui doivent être sauvés, etc). Il est important de séparer ces différents types de données car cela joue un rôle sur l’organisation mémoire que l’on va choisir.
On va prendre un exemple que je connais bien : un chargeur de batterie haute tension. Ce calculateur doit réguler la charge, donc lire des capteurs, et actionner des IGBTs (pour simplifier). L’un de ces capteurs est un shunt de puissance (300A) qui nécessite d’être calibré pour chaque pièce. Il doit contenir un numéro de série unique pour empêcher le vol et pour identifier la pièce en cas de retour SAV. Il doit être reprogrammable par le bus CAN du véhicule, puisque qu’on ne va ouvrir le chargeur pour accéder aux ports JTAG quand on doit faire une mise à jour du programme. Et il doit être utilisable dans plusieurs configurations différentes (chargeur 2kW, 11kW, 22kW, 43kW …). Il nous faut donc:
- Un stockage du code programme
- Un mécanisme de réécriture du code programme
- Un espace pour stocker des données de configuration du produit (type de puissance du chargeur)
- Un espace pour stocker les données spécifiques à la pièce (numéro de série, calibrations du shunt)
- Un espace pour stocker des donnes “de tous les jours” (nombre de charges effectuées, mémoriser les défauts détectés …)
Tout cela va être stocké dans la Flash du microcontrôleur. Les MCUs ont généralement des Flashs découpées en blocs, qui peuvent être indépendants les uns des autres. Cela permet de choisir une architecture mémoire pour contenir ces différents éléments. Pour commencer, on va avoir besoin de séparer le code en deux parties : l’application et le bootloader. Le bootloader est un programme dont la fonction est de permettre de réécrire la Flash, et entre autres l’application. Ces deux programmes seront donc dans des espaces mémoire séparés. Et général, le MCU boote par défaut sur le bootloader, qui vérifie si une application valide est présente dans l’espace mémoire ad-hoc, et va lancer l’application si c’est le cas. Le bootloader a la possibilité d’effacer et de réécrire l’application en recevant le nouveau code par un périphérique de communication. L’intérêt ? Pouvoir reprogrammer sans accéder au JTAG - fragile et dangereux - mais en utilisant un “bus de terrain” déjà existant sur le produit de par son usage. Typiquement, sur une bagnole : le bus CAN. Autre exemple : un routeur Ethernet, dont le bootloader devra permettre de reprogrammer son applicatif via Ethernet, vu que les ports sont déjà présents du fait de la fonction du produit. Ça permet de ne pas ajouter des connecteurs dédiés à la reprogrammation. Il est donc à noter que le bootloader n’est pas censé être mis à jour, effacé, réécrit. En vrai c’est techniquement possible, mais on préfère éviter, car une erreur dans la programmation du bootloader peut briquer le produit.
Ah, tant que j’y pense, les hypothèses à prendre en compte, c’est une généralisation de Murphy: la programmation peut ne pas bien se passer et le transfert via le bus de com peut ne pas bien se passer, donc ça va mal se passer. Il faut donc y être robuste. Quand on a un produit “dans la rue”, ça veut dire qu’il faut garantir qu’on ne se retrouve jamais avec un bootloader qui ne marche pas ou une application qui foire suite à une mise à jour qui s’est mal passée. Et ça explique beaucoup de choses sur les architectures et le fonctionnement des softs embarqués.
De plus il faut prendre en considérations les limitations techniques intrinsèque de la technologie Flash:
- La durée de vie est limitée, dans le temps mais aussi et surtout en nombre de cycles effacement/écritures,
- On modifier les données bit à bit, mais on ne peut pas les effacer bit à bit,
- On ne peut effacer que par page, unité de “mesure” qui contient une certaine quantité de données, qui dépend de la Flash, du MCU, du découpage choisis par les concepteurs du MCU,
Par opposition, l’EEPROM est aussi limitée en nombre d’écritures, mais est par contre effaçable bit à bit. Pourquoi ne pas utiliser de l’EEPROM ? Parce qu’elle prend beaucoup plus de surface sur un die de silicium et qu’elle coûte beaucoup plus cher. Pour ordre de grandeur, les plus grandes EEPROM disponibles sur le marché font 1Mb ou 2Mb (méga bit !) alors que les puces de flash avec interface SPI de taille équivalente (SOIC) font facilement plus de 256Mb. En fait, la Flash, ça ne prend pas beaucoup de place et ça ne coûte pas très cher à mettre sur un die, donc la plupart du temps les MCUs ont beaucoup plus de Flash que de SRAM et que d’éventuelle EEPROM intégrée.
Donc, on va devoir subir les contraintes de la Flash, ok. Qu’est-ce que ça induit ?
Déjà, on va devoir d’une façon générale veiller à ne pas trop user la Flash. Donc:
- Vérifier avant d’écrire de nouvelles données, que ces données sont vraiment nouvelles, et qu’on est pas entrain de réécrire la même chose, ce qui ferait un effacement-écriture pour rien,
- Faire des écritures uniquement globales, c’est à dire ne pas écrire une page par-ci, une page par-là au gré du vent, mais faire une seule écriture globale d’un type de mémoire, stocker en RAM les valeurs modifiées, les utiliser dans l’applicatif en RAM, et attendre un évènement spécifique (demande d’écriture de l’utilisateur ou séquence de shutdown),
- Sur les données qui changent dans la vie du produit, faire une sorte de répartition, ne pas sauver les données toujours dans la même zone de Flash, mais faire un système de tours.
En fonction des technologies et des modèles de MCU, la valeur “effacée” de la flash peut être “tous les bits à 0” ou “tous les bits à 1”. Ce qui signifie que quand on fait une écriture sur un secteur vierge on vient écrire sur les bits concernés la valeur non-effacée : sur un MCU dans la valeur effacée est 0, on vient écrire des 1, et sur un MCU dont la valeur effacée est 1, on vient écrire des 0. Or, si on a écrit un bit, on ne peut pas le faire revenir à l’état “effacé”. La seule façon de faire revenir ce bit à la valeur effacée, c’est de faire un cycle d’effacement.
Or, on ne peut pas effacer autrement que par page, ça veut dire que même si on ne modifie qu’une seule donnée dans la page, on va être obligé d’effacer toute la page. Il faut donc faire systématiquement une copie des données en flash dans la RAM, puis modifier ce qu’on a besoin de modifier dans la RAM, puis réécrire le tout.
Sachant cela, on pourrait se dire qu’on peut économiser des cycles d’effacement en ré-écrivant si on constate que la “nouvelle” valeur ne va que ajouter des bits “non-effacés”. Mais en pratique ça n’arrive jamais. Il faut donc partir du principe que toute écriture en Flash suppose un effacement, et donc un cycle qui diminue la durée de vie.
On va donc, de e fait, définir plusieurs zones dans la mémoire, avec des usages spécifiques:
- La Flash programme (ou PFlash) contiendra le bootloader et l’application, tous deux séparés dans des sous-zones distinctes et délimitées de façon fixes.
- La Flash data (ou DFlash) contiendra les données, et sera découpée en plusieurs sous-zones:
- Les calibrations de l’application (type de produit), on va appeler cette zone “calib”,
- Les calibrations du produit (calibrations capteurs …), on va appeler cette zone “vnfix”, pour NVM fixe,
- Les données qui changent souvent, on va appeler cette zone “nvrol”, pour NVM rolling / roulante.
PFlash
Dans la PFlash, on va donc mettre le bootloader et l’application. Rien de spécial à dire, il faut juste prévoir assez de place, sachant qu’en général l’applicatif prend beaucoup plus de place que le bootloader. Par ailleurs, pour garantir le fonctionnement correct et la bonne programmation, on va définir des petits blocs de donnée, qui ne seront pas du code, mais des marqueurs. En général on a un checksum / CRC, plus ou moins évolué en fonction de ce dont on veut se protéger et de ce qu’on veut pouvoir faire en cas de checksum faux. En général le checksum ne permet pas de corriger les erreurs (il est trop global), mais permet de vérifier que le code téléchargé est correct.
En plus de cela on va ajouter deux petits blocs, qu’on appelle patterns : un pour définir la validité du bloc de code, l’autre pour définir l’invalidité du bloc de code. Pourquoi deux patterns, alors qu’ils ont une fonction complémentaire ? L’idée c’est de séparer la non validité du fait que le code n’a pas été bien téléchargé de l’invalidité du fait que l’on veut faire une mise à jour de l’applicatif, et donc qu’il faut dire au bootloader de ne pas sauter dans l’application. Lorsqu’il reçoit la nouvelle application, le bootloader va vérifier le checksum, et si il est ok, va écrire le pattern de validité. C’est une sécurité supplémentaire. Cela permet aussi d’identifier si un effacement a été interrompu, car si le pattern d’invalidité est écrit, mais aussi le pattern de validité, cela signifie qu’un opération d’effacement a eu lieu et a été interrompue, et donc qu’il faut effacer à nouveau avant d’écrire. Si l’on voit que le pattern de validité est écrit, mais pas le pattern d’invalidité, cela signifie que la Flash a été effacée, mais que c’est l’opération d’écriture qui a été interrompue. Donc pas besoin de faire un effacement, on peut reprendre l’écriture et économiser un cycle. Comme à la fin on va calculer le checksum, si il est faux ça veut dire que l’écriture a foiré, et donc on écrit le pattern d’invalidité (à nouveau) et on est reparti pour un tour. Mais si l’écriture a juste été interrompue sans erreur, on économise un effacement.
Après, les stratégies peuvent changer : ici je décris une stratégie où l”on ava effacer le pattern d’invalidité à la fin de l’effacement, puis écrire le pattern de validité à la fin de l’écriture et du check du checksum. On pourrait s’y prendre autrement.
En fait il y a une hypothèse très importante à prendre sur le système, toujours Murphy : un problème peut arriver à n’importe quel moment, et interrompre n’importe quelle opération (CEM, ESD, coupure d’alim …). Or, écrire le pattern de validité ou d’invalidité est une opération critique … Donc il faut qu’il y ait le moins possible d’instructions différentes pour l’effectuer, pour limiter le maximum le risque d’avoir une interruption du process d’écriture de ces patterns. Donc, par défaut, s’ils ne correspondent pas exactement à ce qu’ils sont censés être, on part du principe qu’ils sont faux.
CALIB
Dans Calib on va mettre les éventuels paramètres de l’application. On pourrait tout à fait se dire que ce n’est pas nécessaire, et qu’on va tout mettre en #define et en #ifdef dans le code, et re-compiler un binaire complet à chaque nouvelle variante. néanmoins, c’est bien de garder en une séparation entre l’application (le code en lui-même), et les paramètres. Bon, aussi, l’une des raisons pour laquelle on fait ça dans l’industrie, c’est que ça permet de se donner l’illusion qu’un même code est réutilisable tel quel sur plusieurs produits (en pratique c’est rarement le cas), mais surtout ça permet d’avoir un espace dédié pour les paramètres qui doivent être tweakés pendant le développement, espace qui sera accessible par les outils de prototypage. Ça permet de séparer très fortement les équipes de développements et les équipes de validation, ces dernières pouvant, sans compilateur, définir les valeurs de paramètres qui vont bien pour leurs manips, et générer un binaire en modifiant juste la partie calibration, et diffuser des softs avec les bonnes valeurs de calibration sans avoir besoin d’un compilateur. Car, en général, il y a deux types de calibrations:
- Des calibrations liées à la variante de produit / système. Par exemple, je reprend mon exemple de chargeur de batterie, si on sépare la carte de commande de la carte de puissance, pour faire une gamme de chargeurs avec des puissances différentes, on peut garder la carte de commande, changer uniquement la carte de puissance, et changer le soft pour qu’il s’adapte à la puissance du produit dans lequel il est. Pour ça, on garde la même application, mais on change les calibrations.
- Des calibrations liées au développement. Sur des systèmes complexes, on peut s’attendre à ce que tout ne se comporte pas comme attendu, et il y aura de la mise au point à faire. Plutôt que de le faire en tweakant les valeurs et en recompilant à chaque fois, il est techniquement plus pratique de les avoir séparées, et de pouvoir les modifier sans devoir recompiler à chaque fois. Dans l’industrie, très très souvent l’équipe de développement est séparée de l’équipe qui fait la mise au point, et donc va utiliser d’autres outils. Ces derniers ont besoin de modifier les calibrations, donc on leur permet en y séparant du code applicatif.
A noter que, typiquement, cette zone n’est pas prévue pour être modifiée depuis le runtime du MCU. Le principe de fonctionnement, c’est qu’au démarrage de l’application on vient charger le contenu des valeurs en Flash dans une zone image en RAM, et l’application va utiliser ces données en RAM. Les éventuels outils de mise au point vont également agir sur cette zone en RAM. Si on veut écrire dans la Flash, il faut re-générer une zone de calibration avec un outil externe, et la reprogrammer via le bootloader. En tous cas c’est comme ça que ça se fait sur les projets sur lesquels je bosse au taf.
Dans mon cas il est hautement probable que je ne tire pas parti de cette séparation, vu que c’est moi qui fait tout. Je vais quand-même le prévoir dans l’archi mémoire, on ne sait jamais, ça pourrait servir.
NVFIX
Ces données vont donc être écrites une seule fois “sorti d’usine”, ou au moins très rarement. Potentiellement, elles devront être modifiables depuis l’appli, donc on les sépare des calibrations.
A priori moi je n’en aurai pas beaucoup, peut-être de la correction de mise à l’échelle par rapport à la fonction de transfert du JFET. C’est typiquement le genre de truc qui permet d’éviter de trier les composants quand on fait de la prod.
D’ailleurs, exemple intéressant : le MXR Phase 90
Il n’y a pas de MCU, c’est de l’analogique, par contre il y a une calibration : le trimmer qui définit la polarisation des JFET. L’idée, c’est que les JFET ont une dispersion importante, et que le circuit ne fonctionne que sur une petit plage du fonctionnement du JFET, plage qui varie d’un exemplaire de JFET à l’autre. Donc, plutôt que de trier, ne garder que ceux qui sont dans la bonne plage, et jeter les autres, on modifie la polarisation du circuit pour s’adapter à la dérive du composant. Ca permet d’adapter le circuit au composant, et pas l’inverse, et donc de ne pas faire de rebus. Idem ici : plutôt qu’adapter le HW au SW, et devoir trier les composants, on adapte le SW au HW, on prend le composant tel qui l’est et on adapte le SW pour qu’il se cale sur sa plage.
Petit aparté : dans le cas du Phase 90, il y a quand-même une étape de tri, car il faut, pour chaque circuit, 4 JFETs, qui n’ont qu’un seul réglage de polarisation, donc ils doivent être appairés par 4. Donc, cette méthode n’élimine pas l’étape de tri, mais elle permet de ne jeter aucun composant, ce qui est tout à fait logique dans une approche de production et de rentabilité, car je pense qu’un potentiomètre par carte coûte beaucoup moins cher que tous les JFETs qui seraient inutilisables du fait du tri. Pour ne pas avoir de tri à faire du tout, il faut mettre un réglage de polarisation par JFET, et donc avoir un protocole qui permet de les régler indépendamment. En DIY ça peut se tenir, d’ailleurs j’ai déjà vu un projet qui fait ça. Ca fait beaucoup de potars, et les potars c’est pas donné, donc il est logique que MXR ai choisi de n’avoir qu’on seul réglage, et de faire un tri de regroupement. C’est l’optimal : on ne perd aucun composant, on a le nombre minimal de potentiomètres (cher) et de réglages en sortie d’usine. Fin de la parenthèse.
NVROL
Ces données peuvent changer très souvent. Donc potentiellement provoquera beaucoup d’écritures, une à chaque fois qu’une de ces valeurs est modifiée. Pour augmenter la durée de vie globale, on va donc éviter d’écrire toujours dans al même zone, et on va définir une série de blocs, et on va changer de bloc à chaque écriture. L’idée c’est que la durée de vie globale de la Flash de cette zone est alors multipliée par le nombre de blocs tournants qu’on définit.
Cela signifie qu’il faut prévoir un mécanisme pour aller automatiquement écrire dans la zone suivante à celle qu’on a lu au démarrage, et garantir que ce soit la zone suivante qui soit prise en compte le coup suivant. Pour cela on peut ajouter en plus des données un pattern de validité et un pattern d’invalidité (encore). Quand on va écrire de nouvelles valeurs, on va écrire les valeurs dans le bloc suivant, puis on écrit le pattern de validité du bloc suivant, puis on écrit le pattern d’invalidité du bloc actuel, comme ça le coup suivant, le nouveau bloc sera le seul a avoir un pattern de validité écrit, et un pattern d’invalidité effacé.
Autre avantage de ce type de fonctionnement : pas besoin de recopier l’intégralité de la page en RAM quand on veut écrire, on peut écrire les datas tranquillement les unes après les autres, “directement” de page à page, et une fois que la copie a été faite et la validité des données vérifiée, on peut effacer la page précédente. Donc ça ne bouffe pas de RAM, contrairement à la NVFIX. Par contre ça bouffe au moins deux pages de Flash, vu qu’il faut pouvoir faire le rolling.
Dans notre cas, dans cette zone on va mettre les presets et réglages mémorisés, les éventuelles wavtables si j’ai des réglages un peu “pointus”.
D’une façon générale, pour la NVM je vais sans doute m’inspirer du code ODrive.
Application numérique
On va prendre un exemple, et on va voir comment on peut faire notre découpage. Jetons notre dévolu sur un STM32F411RC. Dans sa datasheet, page 53 à 56 on a le mapping mémoire. Page 53 surtout, on constate que le Flash est mappée aux adresses 0x0800 0000 à 0x0807 FFFF. De 0x0 0000 à 0x7 FFFF, ça fait 524 288, ce qui correspond bien aux 512kB annoncés (le STM32F411xC a 256kB, STM32F411xE a 512kB). Regardons ce qu’ils disent dans le Reference Manual, le détail est page 44.

Ce qui est assez bizarre c’est qu’il n’y a que la version 512kB. On va supposer que sur la version 256kB il n’y a pas les deux derniers blocs de 128kB. Dans notre cas, il faudrait donc 64kB pour le bootloader, 128kB pour l’application. On prendrait donc les quatre premier secteurs pour le bootloader, le secteur 5 pour l’appli. Il est à noter que, comme écrit page 49 : “The Flash memory erase operation can be performed at sector level or on the whole Flash memory (Mass Erase)”.
Déjà là on voit deux problèmes.
- Il y a peu de secteurs disponibles, donc pour la NVROL on ne va pouvoir faire beaucoup de tours. Et il faut que les secteurs fassent la même taille, donc c’est forcément sur les blocs 0 à 3. Et le bootloader doit être dans le premier secteur, donc c’est focrément entre les blocs 1, 2 et 3.
- Les blocs 5, 6 et 7 font 128kB, et la SRAM fait 128kB … Donc on ne pourra pas en sauver un intégralement en RAM pour faire de la NVFIX. Donc forcément la NVFIX sera dans un “petit bloc”.
Donc il va falloir que je fasse rentrer tout ça dans les premiers secteurs, ceux qui ne font que 16kB.
Alors, déjà, le bootloader. 64kB c’est ce que j’ai en tête de mon taf, mais les bootloaders sont assez complexes, avec des couches de protocole assez fournies. Ici je n’ai pas besoin de tout ça, donc je peux me dire qu’il ne prendra pas 64kB. Idéalement il faudrait qu’il ne prenne que 16kB, ça serait l’idéal, comme ça je le met dans le premier secteur, et tout le reste est libre.
Dans cette note d’application ils montrent un exemple de mécanisme d’émulation d’EEPROM dans de la Flash, c’est ce que moi j’appelle NVROL. Ils utilisent les secteurs 2 et 3, CQFD.
Donc on pourrait partir sur un truc du style :
- Secteur 0 (16kB) : BOOT
- Secteur 1 (16kB) : NVFIX
- Secteur 2 (16kB) : NVROL bank 0
- Secteur 3 (16kB) : NVROL bank 1
- Secteur 4 (64kB) : CALIB
- Secteur 5 (128kB) : Application
- Secteur 6 (128kB) : -
- Secteur 7 (128kB) : -
Comme ça je rentre dans la version à 256kB.
J’ai trouvé un exemple de bootloader taillé pour les STM32 : https://github.com/akospasztor/stm3….
Autre application numérique
Quand même … 8 secteurs seulement, et des pages aussi larges que les secteurs, ça ne me semble … excessif. Les MCUs qu’on utilise au taf ont une granularité beaucoup plus fine. Peut-être que ces modèles-là ont un découpage très brut adapté pour des applications particulières ? Essayons avec une autre sous-famille. Je vais voir la gamme juste en-dessous, les STM32F3xx, par exemple le STM32F303.

Ah oui … Genre rien à voir, on a, en fonction du modèle, entre 32 et 256 pages de 2kB … C’est pas DU TOUT la même granularité ! Et là il n’y a pas de secteurs, donc on fait un peu ce qu’on veut.
Ok, je pense qu’il va falloir que je liste toutes les architectures Flash dispo, pour les intégrer dans ma matrice de choix. L’on peut noter qu’on a deux options:
- Soit je prend une granularité faible (genre le STM32F411) mais il me faut une EEPROM externe pour les paramètres NVROL, donc au moins 4 SPIs,
- Soit je prend une granularité élevée pour faire du NVROL dans le MCU, et pas d’EEPROM externe, donc 3 SPIs suffisent.
Ce qui serait bien, c’est d’avoir quelques gros secteurs, pour code et boot et NVF, et un secteur avec des petites pages, pour la NVROL.
Bon alors, on fait quoi ?
Oui, parce que là on est pas trop avancés. Après avoir passé en revue toutes les docs, dans les STM32 il y a deux “types” de découpage mémoire, en fonction de la sous-famille:
- Quelques (entre 4 et 16) gros secteurs, de tailles différentes, mais la plupart trop gros pour être copiables en RAM,
- Plein de petits secteurs de quelques kB, sans découpage en secteurs.
Si je veux faire de la NVROL, je pense que je suis condamné à choisir un MCU dans cette deuxième catégorie. Il s’agit des familles suivantes:
- F100xx
- F37xxx
- F303x, F328x, F358x, F398x
- L4x5, L4x6
- F334x
- F302x
- F301x, F318x
- L4x1
- L41xxx, L42xxx, L43xxx, L44xxx, L45xxx, L46xxx
- L4xxx
- L552x, L562x
- G0x, G4x
Si je veux un MCU qui tourne à 100MHz, il ne faut du L5 ou du G4. Si j’accepte d’aller un peu moins vite j’ai plus de choix. SI je reste dans les 70-80MHz j’ai quand-même les F1, F3 et les L4. G0 un peu juste (64MHz max). Je n’ai pas regardé les MCUs avec des puissances vraiment trop faibles (moins de 48MHz). En filtrant entre 70MHz et 120MHz, 256kB et 512kB, en boîtier LQFP100, je trouve 10 résultats dans la gamme “mainstream” (en gros les F et G), et 17 en “low-power” (les L), 9 si j’élimine ceux qui n’ont que 6 timers.
En gros mon choix c’est soit du F à 72MHz avec DSP et FPU, soit du L à 80-110MHz, mais sans DSP ni FPU. Donc plus rapide, mais que des opérations simples, ou plus lent mais avec moyen de faire du float et des divisions. Je pense que je vais prendre du F pour ne pas me limiter sur les divisions. Me restent donc 10 candidats.
Parmi ceux-là, les F1 n’ont pas de DSP/FPU, ils sont plutôt conçus pour faire de la com, typiquement du protocole qui demande beaucoup d’opérations simples, pas de maths. Donc je les enlève, il en reste 9.
La flash c’est cher, on ne prend pas plus que ce qu’on a besoin, donc 256kB, restent 5:
- STM32F378VC
- STM32F358VC
- STM32F302VC
- STM32F303VC
- STM32F373VC
Parmi ceux-là, la balance se fait entre timers et RAM / coeurs ADCs. Bizarre, j’aurais pensé que ADCs et RAM prenaient trop de place sur le silicium pour être grossis de concert. Très concrètement, il me semble plus utile d’avoir de la RAM, donc soit 303VC, soit 358VC ou 378VC, (48kB de RAM). Le 358VC et le 378VC s’alimentent en 1.8V semble-t’il, ce qui n’est pas pratique. Restent 302, 303 ou 373. Bon, arbitrairement je choisis celui qui a le plus d’ADC, donc STM32F303VC. 7€ HT chez Farnell, pas énormément en stock mais dispo.
Le gagnant est : STM32F303VC
Maintenant, étape très importante : faire le pinout. Pour ne pas se tromper -> CubeMX
Configuration dans CubeMX
C’est parti. On ouvre CubeIDE et on créée un nouveau projet, on choisit le STM32F303VC. Quand on créé un projet sur un template de MCU, il n’y a RIEN de configuré, même les horloges. On va donc commencer par ça.
Clock
Regardons l’onglet “clock configuration”.
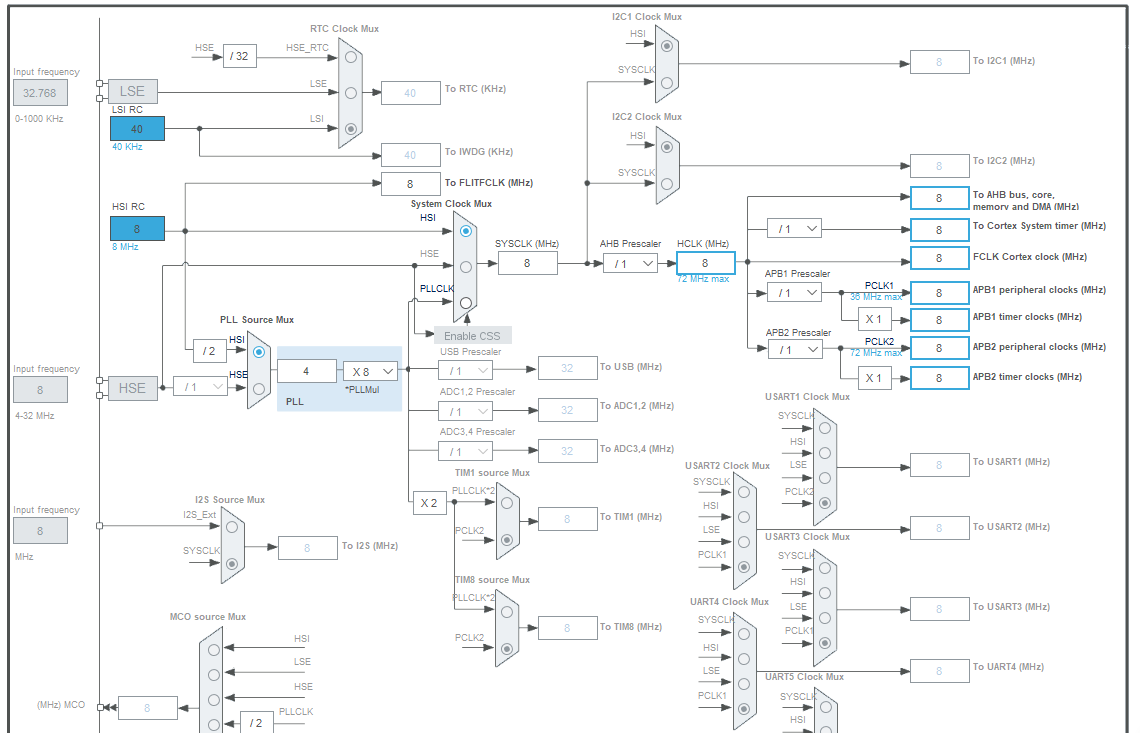
De base, on a pas beaucoup de choix, ce qui est normal, on a rien configuré sur le module RCC (clock et reset), et donc par défaut on est sur la clock interne : HSI RC, fixe à 8MHz. Dans la config de base, cet oscillateur interne va alimenter directement l’horloge système à 8MHz. Si on reste sur cette horloge interne, en sélectionnant “PLLCLK” sur le “System Clock Mux”, on peut augmenter la fréquence système en passant par la PLL. Le “PLL source Mux” ajoute un diviseur par 2, donc on feed la PLL avec 4MHz, et on multiplie ça par le multiplicateur de la PLL “*PLLMul”. Pour atteindre 72MHz, en partant de 4MHz, il faut multiplier par 18. HAN ! Le multiplieur ne peut pas aller au-delà de 16, donc avec l’oscillateur interne on ne peut pas monter au-delà de 64MHz en clock système. C’est assez classique, sur la plupart des MCUs qui ont un oscillateur interne, la fréquence du coeur est limitée, et pour avoir la fréquence max il faut un oscillateur externe.
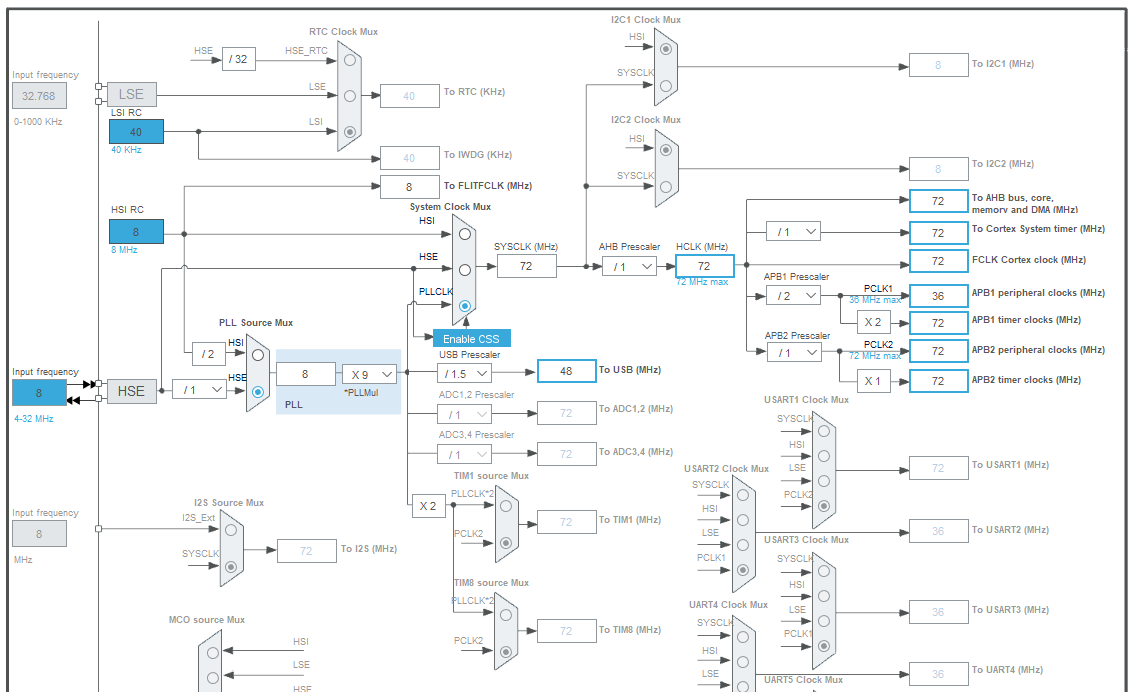
Partons donc sur un oscillateur externe (niveau résonateurs sur Farnell c’est un peu la hess, ça va mieux chez Mouser, ils ont même du Murata). Ça se connecte sur l’entrée HSE (“E” pour “external”, “I” pour “Internal”), et l’on remarque qu’il y a un diviseur dont on peut sélectionner la valeur, et on peut le mettre à 1, donc si on met un résonnateur à 8MHz, on peut feed la PLL en 8MHz, et donc doubler la fréquence par rapport à l’oscillateur interne, ou en tous cas atteindre la fréquence max de l’horloge système. Pour configurer ça, on va dans l’onglet “Pinout & Configuration”, puis dans “System Core” et “RCC”, et dans le champ “High Speed Clock (HSE)” on choisit “Crystal/Ceramic Resonator”. Si on revient à l’onglet “Clock Configuration”, on a maintenant l’entrée HSE qui est dé-grisée. “Input frequency” c’est la fréquence du résonateur qu’on va choisir, on peut monter jusqu’à 32MHz. En valeurs standard on a 20MHz, ou 8MHz, on va choisir ça. Diviseur en entrée de la PLL : 1, “PLL Source Mux” sur HSE, “System Clock Mux” sur PLLCLK, et “*PLLMult” à 9 pour atteindre 72 MHz sur l’horloge système SYSCLK. Ça se met à gueuler sur l’horloge APB1 parce qu’on dépasse la fréquence max de 36MHz. Ça tombe bien, ya un diviseur dédié, on le met à 2 et ça met la fréquence à 36MHz.
Petite remarque au passage : on constate qu’on a une fréquence de 36MHz pour les timers, ce qui peut ne pas être pratique pour faire des mesures de temps “standard”. Dans notre application ce n’est pas très grave, mais si on fait par exemple de l’échantillonnage audio, à 44.1kHz ou 48kHz, on peut se retrouver avec des valeurs pas rondes, donc il peut être intéressant de se démerder pour avoir une fréquence de périphérique qui est un multiple entier de la fréquence d’échantillonnage que l’on veut (il y a un prescaler qui va diviser par un entier, on divise toujours par des entiers les fréquences d’horloge), quitte à devoir mettre une fréquence système qui n’est pas la fréquence max, mais qui est à une valeur qui nous arrange pour avoir le bon échantillonnage sur le périphérique. Dans notre cas on a aps ce genre de contrainte … A part pour l’USB, qui est très chiant sur les fréquences de fonctionnement, et la précision de fréquence, car c’est de la com asynchrone très rapide. D’ailleurs, on va check ça tout de suite.
USB
Allons dans l’onglet “Pinout & Configuration”, “Connectivity”, USB, et on coche “Device (FS)”. L’onglet “CLock Configuration” passe “pas content”. Quand on va dedans, il nous propose de résoudre les problèmes de conflits, et si on dit oui, il va mettre le “To USB” à 48MHz, qui est la fréquence requise pour le fonctionnement des périphériques USB. Par contre, pour faire ça, il a dû descendre la fréquence système à 48MHz aussi …
Mais mais mais mais mais, il y a un “USB Prescaler” juste avant, et quand on ouvre le menu déroulant on voit qu’on peut lui donner deux valeurs : 1 ou 1,5. Bizarre, je suspecte un trick pour avoir un diviseur fractionnaire. Toujours est-il que si on choisit 1,5 on peut alors remonter le PLLMult à 9 et donc remonter la fréquence système à 72MHz. Ils ont pensé à tout :)
On arrive donc à ceci:
Instancions maintenant les périphériques de com, ceux qui ont des pins dédiées.
SPI
Onglet “Pinout & Configuration”, Connectivity. SPI1, on va la mettre en Master Full-duplex, ça sera la com pour le digipot du gain. Là on peut soit assigner une deuxième SPI dédiée à celui du circuit de référence, ou bien se dire qu’on le gérera avec u nchip select. Par défaut, activons le SPI2 en Master Full-Duplex aussi, dans le doute. Au fur et à mesure, il va assigner automatiquement les pins. Puis SPI3, on va le mettre en Transmit-only, ça sera pour les bit-shifters et l’affichage.
UART
On a dit : un pour le debug / ST-link, un pour la com directe avec un FTDI derrière, et deux pour le MIDI. Sachant qu’on peut être économes et se dire qu’on ne met qu’un UART pour le MIDI, le RX pour le IN et le TX pour le OUT.
De toutes façons on peut mettre un peu l’UART que l’on veut sur la fonction que l’on veut, ça ne change pas grand chose. Donc prenons UART4, on le met en Asynchronous, Receive & Transmit, idem pour UART5, et USART1, qu’on peut configurer en asynchrone, donc que ce soit un périphérique synchrone ne change rien. On a un conflit avec l’USB, mais sur les signaux de contrôle qu’on ne va pas utiliser, donc c’est bon.
ADC
On a dit qu’il faut 10 entrée, et bien allons-y. Sur ce MCU il y a 4 coeurs, ADC1 a 9 entrées, ADC2 an a 11, mais 2 sont en conflit et inutilisables, ADC3 et ADC4 ont 15 et 12 entrées, dont déjà des conflits. Toujours dans l’onglet “Pinout & Configuration”, on va dans “Analog”, si on commence sur ADC1 et ADC2, je peux activer les 4 premières entrées de ADC1 et les 4 dernières de ADC2. Hors conflit, sur ADC3 et ADC4 j’ai accès à PB0, PB1 et PB12. Bon, pour éviter de me compliquer, je vais rester sur ADC1 et ADC2, je met la 5e entrée sur ADC1, et la 9e sur ADC2.
Timers et PWM
Un truc un peu relou avec les timers et PWM sur les STM32 : la répartition des APB. Tous les timers ne sont pas clockés par le même bus, certains sont sur l’APB1, d’autres sur l’APB2, qui peuvent être à des fréquences différentes. Pour savoir que timer va sur quel bus, il faut check dans la datasheet ou le reference manual, chercher le clock tree:
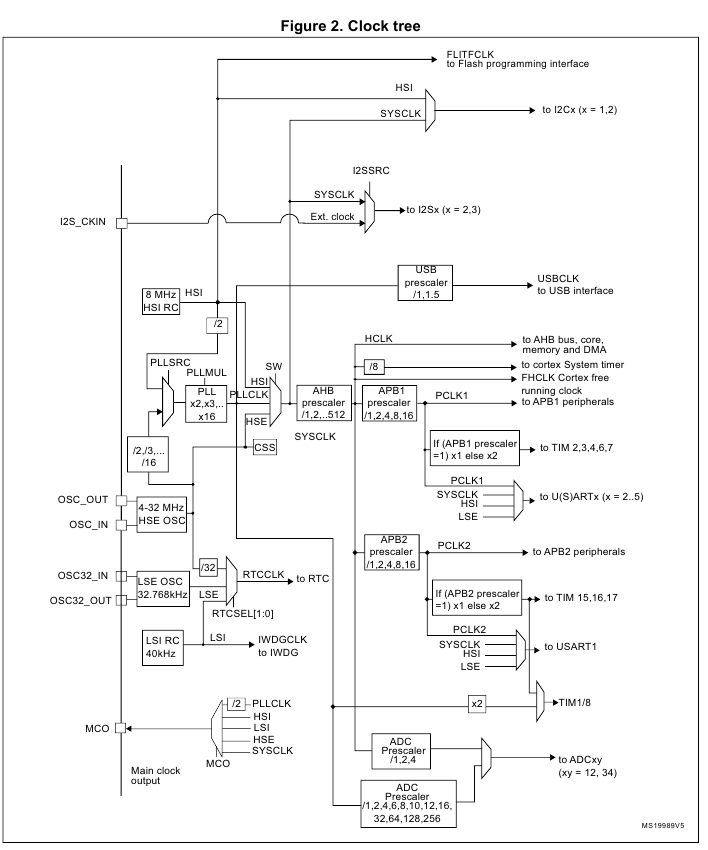
Et l’on voit donc que les TIM1 et TIM8 sont sur une ligne séparée, alimentés directement sur PLLCLK (ou APB2), sinon TIM2, 3, 4, 6, 7 sur APB1 et TIM15, 16 et 17 sur APB2.
Pour ne pas faire des archis trop compliquées, on va peut-être éviter d’instancier tous les timers, et regrouper un peu. Ici ce qui compte surtout c’est de configurer le pinout, donc les PWMs. Il en faut 4, et 3 input capture. Avoir les IC indépendants c’est beaucoup plus pratique, surtout si on mesure des signaux dont la fréquence peut avoir des valeurs totalement arbitraires (ce qui sera le cas ici), donc on va chacun leur alouer un TIM dédié. Pour les PWMs, si le matriçage des sorties le permet, ne mettre qu’on seul TIM pour les 4 ça suffira. Et le reste servira pour trigger les tâches applicatives.
Mais … Il faut quand-même réfléchir un peu. Les input capture vont devoir mesurer des signaux de fréquence très arbitraire, et surtout qui peuvent descendre très bas, genre quelques dizaines de Hertz, voire moins. Or, les compteur sont pour la plupart en 16 bits, seul TIM2 est en 32 bits. Ça ne fait pas une résolution énorme, et surtout ça veut dire qu’on ne peut pas avoir une fréquence très élevée pour les clocker, sinon ils n’iront jamais “assez lentement”. Si on prend une hypothèse d’une plage de fréquence de 20Hz à 20kHz, en 16 bits (65536 valeurs), ça fait une fréquence de \~1,3MHz pour pouvoir mesurer …. C’est très très bas.
On peut se dire que, ça tombe bien, ya trois timers qui sont “isolés” sur le même bus APB2 : TIM15, TIM16 et TIM17. Mais pour baisser la fréquence aussi bas, pas évident. Ya un prescaler sur APB2, mais il ne va pas au-delà de /16, et pour les timers c’est x2, donc avec 72MHz en horloge système on ne descend pas en-dessous de 9MHz. Oui mais oui mais oui mais, ils ont pensé à tout, et pour chaque timer il y a un prescaler dédié, dont la valeur est codée sur 16 bits. Donc pas besoin de descendre la fréquence du bus, on peut ajuster avec le prescaler.
Donc, si on part sur une valeur de prescaler qui permet de descendre à 1.3MHz virtuels il faut 72 / 1.3 65535 pas pour la période de 20Hz, combien ça fait de pas pour une période à 20kHz ? 1,3MHz -> 770ns, 20kHz -> 50µs, donc 50 / 0.77 = 65 pas, ce qui n’est pas dégueu. On pourrait même descendre un peu pour avoir un peu de marge. Si on met un prescaler à 64, on a 1.125MHz, on descend à 17Hz, 56 pas à 20kHz. On va partir là-dessus.
Pour rappel : le fonctionnement des sorties PWM sur les STM32. Chaque TIM est un timer, qui dispose de plusieurs “channel”. Il n’y a qu’un seul compteur et une seul registre de reload, mais chaque channel a son registre de comparaison et peut être connecté à une pin, en entrée (input capture) ou en sortie (PWM). En pratique, cela signifie qu’un TIM peut dirver plusieurs sorties PWM (une par channel activable) mais ils auront tous la même fréquence, vu que le compteur et le registre de reload est commun. Par contre, chacun pourra avoir un rapport cyclique indépendant. Pour les input capture c’est beaucoup moins pratique, surtout si les signaux en entrée sont de fréquence différente et non synchronisés entre eux. Donc il est préférable d’avoir un TIM par input capture. Par contre, si on peut tolérer d’avoir des PWM de même fréquence et de période synchrone (c’est le cas ici) on peut utiliser plusieurs channels sur un même TIM pourr faire des sorties PWM différentes.
Donc, dans l’onglet “Pinout & Configuration”, Timers, déjà on constate que TIM6 et TIM7 sont des “basic timers”, pas vraiment utilisables pour grand chose, normalement ils sont prévus pour trigger le DAC, qu’on utilise pas. Donc restent TIM1, TIM2, TIM3, TIM4, TIM15, TIM16, TIM17. Je propose de prendre TIM4, TIM16 et TIM17 pour les input capture, TIM3 pour les PWMs des VCOs, TIM1 pour les PWMs des DACs.
Encore une autre remarque : certaines interruptions sont partagées entre les timers. Genre TIM1 partage certaines de ses interruptions avec TIM15, TIM16 et TIM17. Donc, bon, tant qu’on utilise pas les interruptions de TIM1 c’est bon, donc le mettre en sortie PWM ça va le faire, on a pas besoin des ses interruptions dans ce mode.
On va activer les 4 sorties de TIM3, qui servira pour les PWMs des VCOs. On va utiliser TIM1 pour les PWMs des DAC, donc on activer deux sorties. Pour activer un timer, on met “Clock source” sur “Internal Clock”, et sur chaque channel qu’on veut activer on sélectionne “PWM generation CHx”. Tant que c’est pas en rouge, c’est qu’on a le droit.
Au passage : il est de bon ton de mettre des labels custom pour s’y retrouver. Mais visiblement on peut pas le faire sur le PWMs …
DAC
On va l’activer quand-même, pour test, pour voir si on peut en faire quelque chose. C’est une provision, on verra ce qu’on en fait, et si ça sert vraiment comparé à un DAC à base de PWM, surtout qu’il n’a que deux sorties, alors qu’il en faudrait 4 pour le système complet. Juste, truc relou : il a deux sorties et la deuxième sortie est en conflit avec le SPI1. Ptet il vaut mieux que je désactive la SPI1 et que je multiplexe vraiment les deux digipots sur SPI2 ?
GPIO
Je ne vais pas mettre d’entrée d’interruption, je ne vois pas d’entrée qui demande une telle rapidité de réaction. Donc pour les entrées on va se contenter de faire du polling. Ca va être un peu limite pour les entées des encodeurs, mais bon …
Pour assigner des GPIO dans CubeMX c’est pas du tout pratique, il faut aller les sélectionner sur le plan de la puce, et sélectionner “GPIO_input” ou “GPIO_output” en fonction de ce qu’on veut. Listons ce qu’il faut:
- OUT CS pour le digipot 1 - J’active la sortie NSS, plus simple
- OUT CS pour le digipot 2 - Idem
- OUT CS pour les shifters
- OUT Latch pour les shift registers
- OUT red pour encodeur 1
- OUT green pour encodeur 1
- OUT blue pour encodeur 1
- IN bouton encodeur 1
- IN CW encodeur 1
- IN CCW encodeur 1
- OUT red pour encodeur 2
- OUT green pour encodeur 2
- OUT blue pour encodeur 2
- IN bouton encodeur 2
- IN CW encodeur 2
- IN CCW encodeur 2
- IN bypass
- IN preset +
- IN preset -
- OUT LED bypass
- 3 x OUT pour un multiplexeur éventuel
Ca fait un total de 21 GPIO. Les GPIO étant, comme leur nom l’indique, “general purpose”, on peut les assigner comme on veut, donc il ne faudra pas hésiter à changer le mapping pour faciliter le routage.

Pins de debug
Les pins de debug SWD sont à configurer. Dans la doc “hardware development” on trouve le pinout du port SWD:

En fait si, c’est dans l’onglet “System Core” / “SYS” et on peut choisir le tye de debug.
Or, on a un souci : ça entre en conflit avec d’autres fonctions. Entre autres la clock de la SPI3 est en PB3. Bon, CubeMX est assez mal foutu pour ce qui est de configurer les pins.Quand on active un périphérique, il va automatiquement configurer les pins correspondantes. Par contre, si une des pins peut être mappées à plusieurs endroits, pour changer sa position il faut le faire sur le plan du pinout … et donc savoir à l’avance quelles sont les différentes pins possibles. Donc : datasheet, tableau de pinout. On cherche SPI3_SCK, il y a visiblement 2 pins possibles : PB3 ou PC10, mais PC10 est le TX de UART4, et il n’y a pas d’alternative. Donc on ne peut pas utiliser le SWD + SPI3 + UART4. Quand je dis qu’il faut toujours check le pinout complet …
Donc on désactive UART4 et on prend USART3 à la place, ce qui libère PC10 et permet d’y mettre SPI3_SCK,et donc de configurer PB3 en SWD.
Ensuite PB4 est aussi l’entrée du channel 1 de TIM16, donc il faut le mapper ailleurs, ou changer de channel. Là on a plus de choix : PB4, PA6, PA12, PB8. Ce dernier est libre, je le prend.
Au final, en activant tout ça, je me retrouve avec UART2 et UART4 qui ne sont pas utilisables. Comme quoi il faut se méfier sur les specs des périphériques dispo sur un MCU : en pratique on ne peut pas tout avoir à la fois, et il faut toujours vérifier le pinout exact avant de se lancer.
Schéma
Maintenant il faut attaquer le schéma. Pour l’alim je me base sur le doc “hardware development”, et je mets le même nombre de capas qu’ils mettent sur le schéma d’application.
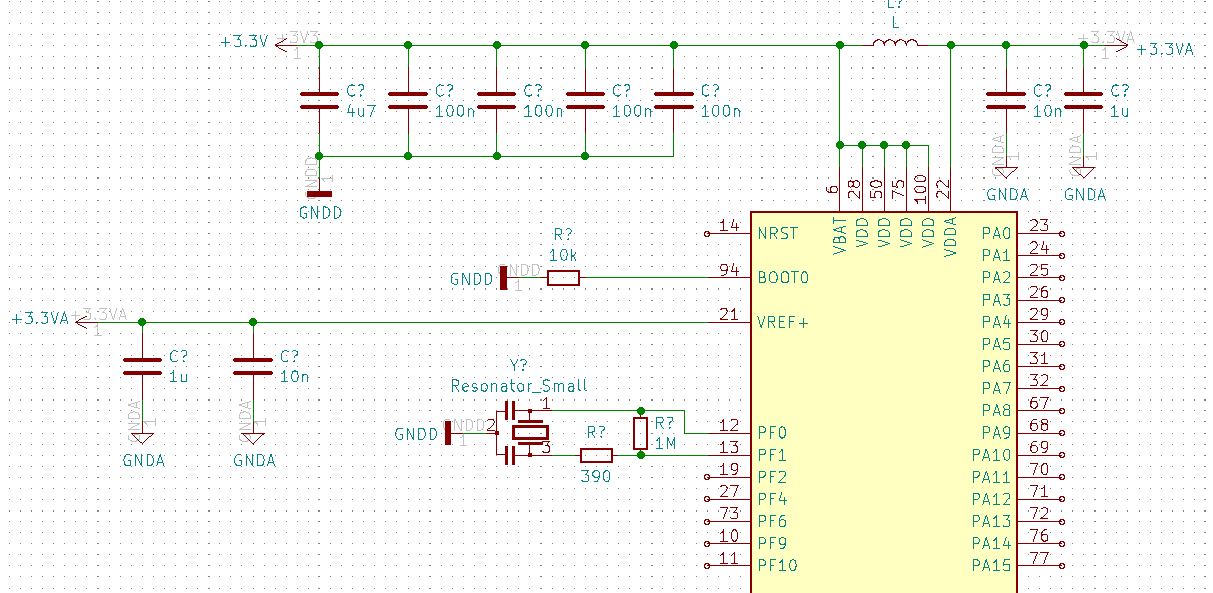
J’ajoute une self (je mettrai une petite, genre BLM18 ou équivalent) entre le 3.3V de la partie numérique et l’alim des ADCs. Je mets une résistance de 10k à la masse sur le BOOT0, pour pouvoir, le cas échéant, tirer la pin à 3.3V pour le faire booter sur son bootloader interne.
On commence à être pas mal. Je vais faire un autre article pour l’implémentation de la partie analogique.
Par contre, coup de stress sur la BOM:
358 composants.
TROIS
CENT
CINQUANTE
HUIT !
Et j’ai pas encore fini la saisie du schéma … Ca devient vraiment un circuit énorme. Le routage et le montage vont être … hum … sympatiques !
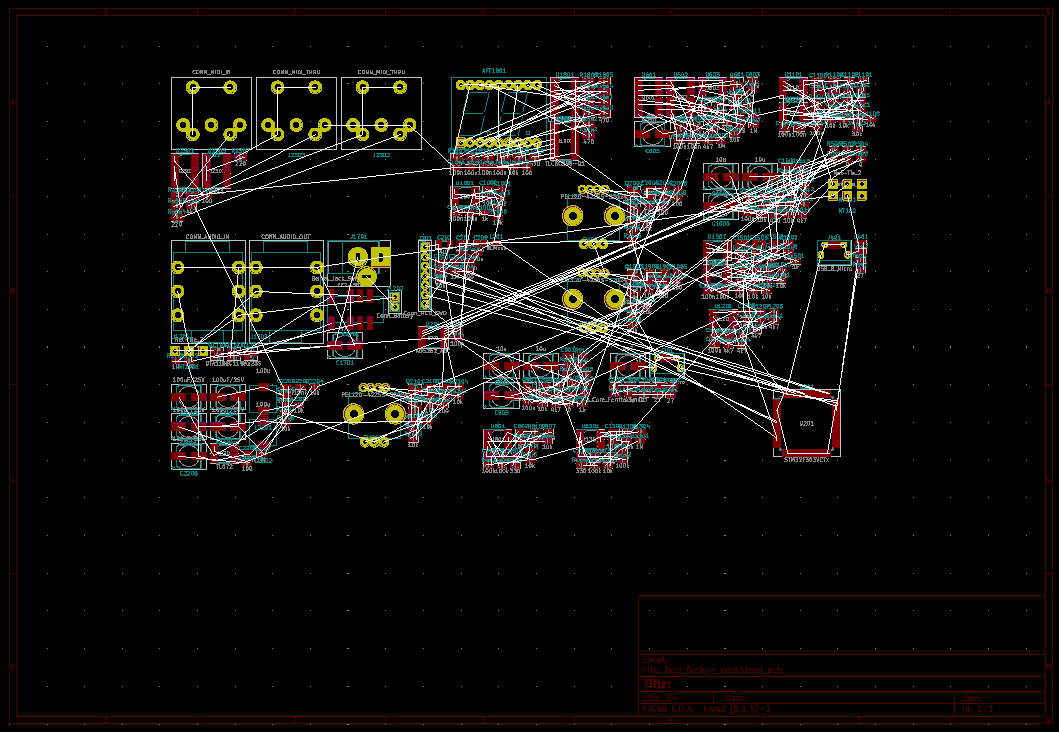
Et aucune garantie que ça donne quelques chose d’exploitable. Merde … Dans quoiest-ce que je me suis encore embarqué ? Entre ça et stm32doom, je commence à avoir l’impression que mes projets sont trop compliqués et voués à l’échec :(